根本的な問題は労力ではなく、ばらつきです。仕入先ごとにデータの送り方が違うのに、PIMのスキーマは固定。誰かがすべての形式を翻訳しなければなりません。手作業で。すべての商品について。カタログ更新のたびに。

仕入先AはExcel、BはPDFの文章、Cはサイトのエクスポート——すべてが手作業の翻訳を経て、1つの硬直したスキーマに流し込まれます。
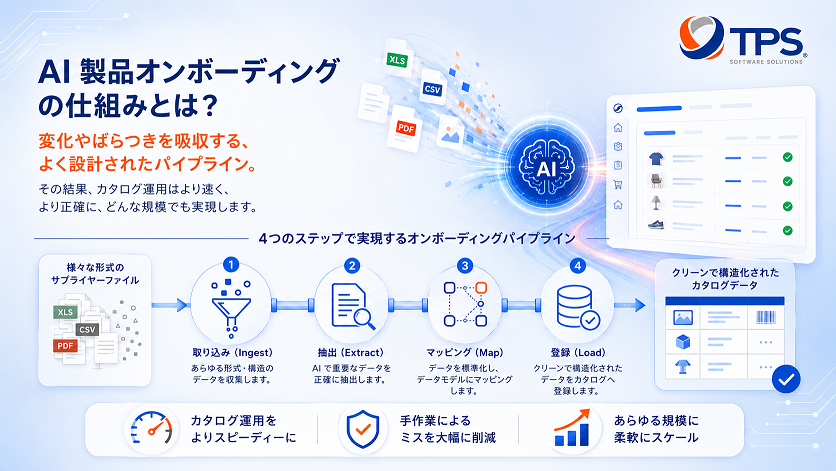
4段階のパイプライン
AI商品オンボーディングは、その手作業の翻訳レイヤーを設計されたパイプラインに置き換えます:取り込み → 抽出 → マッピング → 投入。各段階が実際に何をするのかを見ていきましょう。
ステージ1:取り込み — 何でも受け入れる
TPS AI商品オンボーディングは、Excel・CSVファイル(任意の列構成)、PDF文書(テキストベース・スキャンの両方)、メタデータが埋め込まれた商品画像、サイトのエクスポート、そして仕入先システムとの直接API連携を受け入れます。手作業での前処理は一切不要です。

ステージ2:抽出 — AIが読み取り、理解する
テキストベースのファイルでは、列名が非標準でも欠けていても、NLPが商品属性を特定して抽出します。非構造化テキスト(PDFの文章)では、固有表現認識が寸法・素材・色・重量・価格・バリエーションといった具体的な属性を抽出します。スキャンされたPDFや画像では、まずOCRがテキストレイヤーを抽出します。抽出された内容にはすべて信頼度スコアが付与されます。信頼度が高い抽出結果は自動でマッピングされ、信頼度が低い項目は人によるレビュー対象としてフラグが立てられます。

ステージ3:マッピング — 自社スキーマに整合させる
抽出で得られるのは、生の属性です。マッピングは、それらを自社固有のデータ構造へと変換します。TPS AI商品オンボーディングは、設定時に自社スキーマ——フィールド、必須属性、カテゴリ構造、バリデーションルール——を学習します。たとえば仕入先が「Gross Weight Including Packaging: 4.2kg」を送ってきて、自社スキーマに「shipping_weight_kg」があれば、システムはそれを正しくマッピングします。

ステージ4:投入 — すべてのシステムへ反映
データが抽出・マッピングされると、正規化された上で、PIM・OMS・店舗・倉庫/WMSへ同時に反映されます。画像処理も並行して実行され、背景除去・レタッチ・品質チェックが、データ投入と同時に完了します。

実環境でのパフォーマンス
処理量はカタログ規模に応じて予測どおりにスケールし、誤り率は手作業と比べて大幅に下がります。
| カタログ規模 | 処理時間 |
|---|---|
| 500 SKU | 30分以内 |
| 2,000 SKU | 2時間以内 |
| 10,000 SKU | 6時間以内 |
| 25,000 SKU | 12時間以内 |
| 手作業比の誤り率 | 約95%削減 |