
“Oil was no longer the world’s most valuable resource, instead, it was data,” claimed the Economist. The beneficial application of data into technology bringing positive transformation for businesses has certified the statement. Data has fueled artificial intelligence and variously applied to all the spectacular advances. Data is the fuel that can be leveraged to create new products and services, or improve the existing ones. Companies and corporations are starting to realize the inherent value contained in their data and looking forward to solutions that can enhance business efficiency.
Data is valuable and plentiful, but how much data do we need?” and how to use data wisely for an AI project?
When working with data, there is no perfect amount needed. Most companies struggle to provide high-quality datasets. Many problems can arise when carrying out data due diligence. Usually, the datasets under scrutiny fall short in at least one of these categories:
- Completeness: Are there missing records?
- Quality: Are the records correct?
- Quantity: is the amount of data limited
- Accessibility: Can the data be accessed
- Connectivity: Can the different datasets join?
- Validity: Does the data contain outliers?
However, some of these aspects are more critical than others and more or less hard to fix. In some cases, missing records can be backfilled or inferred, and mistakes can be corrected based on rules or logic, etc. But, if the data is sparse, it might be difficult to collect more data in terms of time or cost.
This article provides an insight into state-of-the-art techniques dealing with limited or incomplete data and a broad understanding of the methods to address this challenge.
How much data is enough for an AI project?
The proper size of the dataset can depend on many factors such as the complexity of the model, the performance, or the time frame. Usually, machine learning engineers will try to achieve the best results with the minimum amount of resources (data or computation) while building their AI predictive models. This means that they will first try simple models with few data points before trying more advanced methods potentially requiring vast amounts of data.
So before determining the quantity of required data, figure out the model that you are working on, is it a linear model or a quadratic model?
A linear model is between target variables and your features as a linear model has two parameters only (y = a*x+b). Two data points are generally enough to fit a straight line.
If the model you are working on is a quadratic one with three parameters (y = a*x²+b*x+c), you’ll need at least three data points, etc. Usually, even if there is no one-to-one relationship, the more complex your model becomes, the more data you will need to determine its parameters.
Finally, there are actual mathematical ways to figure out whether you have enough data. Let’s say that you are working on a model and have reached the best possible performance with the data at hand, but it’s just not enough. What should you do now? Collect different data? Collect more of the same data? Or, should you collect both to optimize your time and efforts? This question can be answered by a diagnostic of the model and data through a learning curve, which shows how the model’s performance increases as you add more data points as depicted in the below figure.
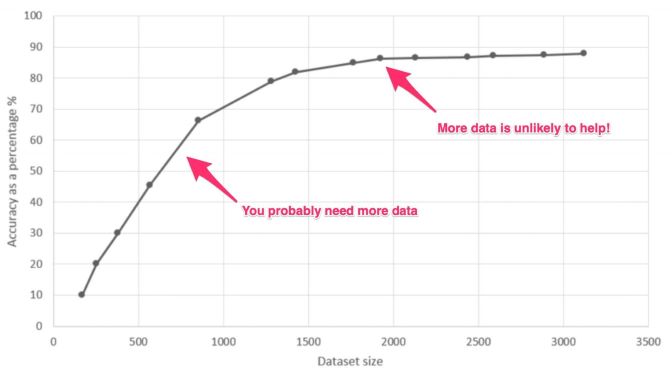
Model’s performance as a function of the training dataset size.
Source: Researchgate
The idea is to see how much the model’s performance benefits from adding more data and whether or not the model has already saturated, in which case, adding more data will not help.
Solutions for data shortage
If you find yourself in a situation where you need more data, there are different strategies to consider depending on the problem at hand and your situation:
1. If collecting data is impossible
If you are unable to collect more data, you can try to resort to either data augmentation, data synthesis, or creating artificial data based on the data you already have.
- Data Augmentation – consists of generating new data points based on the ones you already have. For an image dataset, it requires to create new images with lower or higher resolutions, cropped, rotated, with linear transformations, or added noise. This would help your algorithm become more robust to these types of perturbations. For further reading, have a look at unsupervised data augmentation.
- Data synthesis – is sometimes used to remedy classification problems where one class is imbalanced. New data points can be created using complex sampling techniques. More recent and advanced methods leverage the power of deep learning and aim at learning the distribution (or more generally a representation) of the data to generate artificially new data that mimics the real data. Among such methods, one can mention variational autoencoders and generative adversarial networks.
- Discriminative methods – when data is limited, you want to make sure that you focus on the right part. A common technique is called regularization, where you penalize “non-important” data to give more weight to relevant data points, thus reducing the model complexity. More recently, in the realm of deep learning, a method called multi-task learning is used to exploit the limited amount of data at hand and alleviate overfitting in single-task model training. In essence, you are training several models instead of one to generalize new data better.
However, data augmentation and synthesis will most likely have marginal effects if your data is not well distributed, or too small in size to make use of the above-mentioned methods. In that case, you will have no other choice but to go out and collect new data points.
2. If collecting data is possible
If collecting more data is the way to go, either because it is affordable to collect more data or because you have access to large amounts of data— even partially complete data such as unlabeled data — you have two options:
- Data Collection – is always the first option to consider. If your resources are limited and you have access to domain experts (aka SME, Subject Matter Expert) who can help you qualify (label) your data, you may want to have a spin at active learning. With active learning the process of learning is iterative: the algorithm is trained on a limited number of labeled data, then the model identifies difficult unlabeled points and asks interactively for an SME to label the data point, which is in turn included in the training set.
- Data Labeling – is about using the data points that you already own, but which are not part of your training or testing data (i.e. data used for modeling) because they are incomplete (e.g. missing label data). In that case, it might be interesting to see how you can leverage the latest advances in AI to make use of this untapped data potential.
3. How to label unlabeled data
If you’ve already recorded a significant amount of data but missed some parts of the information as the label, you could, of course, try to retrieve this information manually (data collection with traditional supervision), but it can turn out to be a slow and painful process.
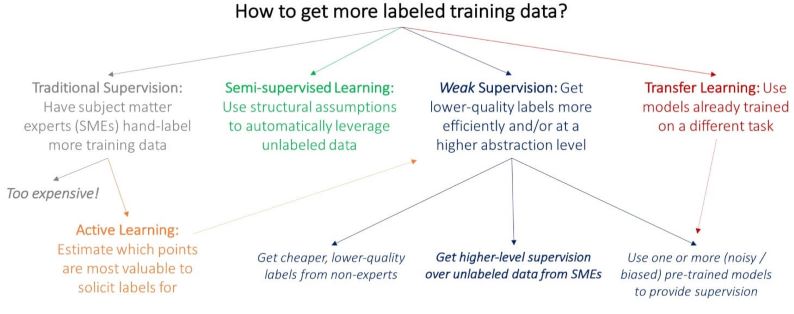
Different approaches to address the lack of data.
Source: Stanford.
There are three major routes that you can try in order to get more usable data from unused and unlabeled data
- Semi-supervised learning: A small amount of labeled data and a large amount of unlabeled data. The idea is to use both the labeled and unlabeled data to achieve higher modeling performance either by inferring the correct labels of the unlabeled data or by using the unlabelled data if possible. Semi-supervised learning makes specific assumptions about the topology of the data, i.e. points being close to each other are assumed to belong to the same class.
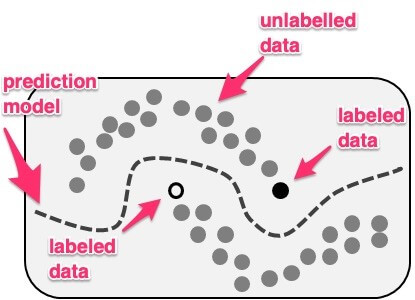
Illustration of a case for semi-supervised learning where it demonstrated the use of unlabeled data (gray points) in order to determine the right model (decision boundary as a dotted line).
Source: Wikipedia.
- Transfer learning –a research problem in machine learning (ML) that focuses on storing knowledge gained while solving one problem and applying it to a different but related problem. This way, the model will become really effective at differentiating between a couple of new categories of interests. This approach, however, requires that you have access to an already pre-trained model and that you can actually use transfer learning with these models, which may not often be the case. Transfer learning can, in some ways, be considered as a weak supervision method.
- Weak supervision – The rationale behind weak supervision is to use noisy data (low-quality data) in order to find missing information in your existing data. The case for weak supervision is relevant when a very large number of labeled data is needed, and a certain level of domain expertise is available to be leveraged. Weak supervision is not applicable to all cases of a limited dataset.
To sum up, there is no fatality in case of data shortage, and that many solutions already exist to address that common challenge. However, it can be somewhat difficult to identify which approach might be best suited for you.
If you are interested in developing an AI project and keen on a deep consultation about data for the project, do not hesitate to contact us.
Our R&D team with high expertise in Data Science and Artificial Intelligence may help you accelerate your AI software development
Source: 2021.ai
———————————————————————————————–
TPS Software is one of the top software outsourcing vendors in Vietnam, which recently has been known for great ability in Artificial Intelligence when excellently became the only representative coming from Vietnam to the FINAL PITCH of ASEAN HEALTHCARE FINTECH ALLIANCE CHALLENGE organized by Alibaba Cloud, Pritzer, and Fintech Academy with solution Joy ID– Hospital: Artificial Intelligence solution designated for patient onboarding process at hospitals. Also, the solution got into the final round of the national AI Solution contest which has been in the process of looking for the winner.
TPS software provides a variety of AI services including AI consulting, AI research and development, AI as a service.
Contact TPS Software for any concern you have on deciding to develop an AI project to have a free consultation.












